No, AI won't steal your programming job
I
I'm not convinced LLMs are an existential threat to software engineers.
I say this from the unique position of somebody who extensively uses Claude Code and desperately needs to hire software engineers. For context, I bought credits within minutes of receiving my Claude Code invite, which quickly ballooned to >$100/week, and has now gracefully stabilized into the Claude Max plan.
People tend to catastrophize. The fear that "AI will eat software jobs" was one of first things tech Twitter clamoured about when videos of GPT-3 writing basic React components went viral. Fast forward to today, when AI is doing vastly more complex work, that fear has risen to a level that would make Stephen King envious.
That fear needs to be contextualized. In broad strokes, there are two classes of engineers:
- Product — tend to be more passionate, care about UI/UX, love Steve Jobs
- Quality — they resolve issues, care about test coverage, love getting home from work
The Product folks have a robust moat: a gestalt of experience, skill, intuition, taste—things that constitute what we call "intelligence"1 or "soul". When a Product person writes an LLM prompt, they're doing so by compressing their intelligence.
The Quality folks are protected by the same moat, but it's narrower and shallower. Their job function is essentially checking off items on a to-do list, whether it be feature requests, improvements, bugs, etc. Using modern LLMs, a surprisingly large number of features and bugs can be automated with a prompt and recursion2. This is where the near-term job-loss risk is most relevant.
In essence, my argument is that high quality prompts will keep engineers employed. Further, since human intelligence, at a high level, is vastly superior to that of neural nets, the fear of job erosion is overblown.
I've also sketched a chart to illustrate my argument:
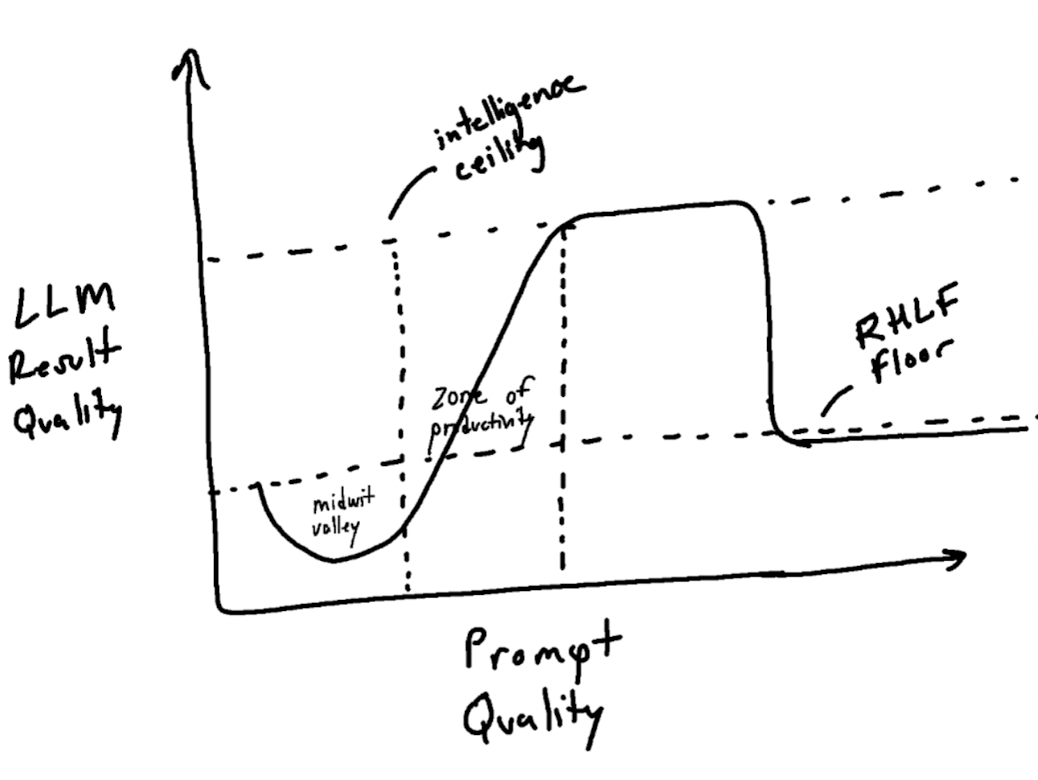 Figure 1. A sketch illustrating the relationship between LLM Quality and Prompt Quality.
Figure 1. A sketch illustrating the relationship between LLM Quality and Prompt Quality.
LLMs powering ChatGPT and Claude are useful because they've been RLHF'd from a more crude precursor state. These LLMs have what I call the "RLHF Floor": even if you enter a really dumb prompt, the LLM will try to be useful and help you achieve your goals.
Following that floor, the graph dips down into the "Midwit Valley". This is where the prompter has somehow managed to get such poor results that they fall below the RLHF floor. For example, a novice might ask ChatGPT to "write an essay on WW2" and get a disappointing low quality result. A more experienced person would prompt several times—first maybe iterating on thesis ideas, then essay outlines, then going section by section, then using stylometric techniques to rewrite the essay in their unique style. That happens in the "Zone of Productivity": a linear ascension where your creativity in the prompt will yield increasingly better results from the LLM.
The graph starts to plateau once you reach the LLM's intelligence ceiling (e.g. you can repeatedly ask it to improve your code maybe 4-5x before the deltas begin to diminish). Past that point, you drop back down to the RLHF Floor: unfortunately, the LLM can't "cure a disease for you and help you win a Nobel Prize" no matter how much creativity and ingenuity you apply in your prompt.
Now swap "Quality" on each axis for “Intelligence” to see why I think modern (and near term) AI isn’t a huge threat to competent software engineers.
II
When I was a kid, I thought Roombas (the robot vacuums) were next-level. We brought one home and my excitement quicky turned to boredom as I watched it move like a sloth and bump into walls, chairs, table legs before finally giving up and docking. I had a similar experience with Claude Code which led me to write this post.
In short, I had Claude translate a list of English strings into another language. However, it failed 3x toward the end while trying to merge data. I (who was multi-tasking) came, saw, and intuited the error from years of experience. I instructed it to use Levenshtein distance to match unpaired keys. Boom, it worked.3
LLMs have limits, and those limits become painfully clear when you assign them increasingly more responsibility. Another way to think of it is that LLMs are just amplifiers. If a computer is a bicycle for the mind, LLMs are like a jetpack. You go further, faster—but you still need someone who knows how to operate the jet pack; not someone who’s going to go out in a big, spectacular fireball.
- "Intelligence" here is not referring to "smart" or "educated".
- E.g. Claude Code can bypass permissions inside a Docker container. Your prompt, for example, could essentially be "fix this issue: we expect X, but see Y. keep trying until the issue is resolved"
- In trying to merge two dictionaries together (where the keys were English words and/or phrases), some keys did not match even though they looked exactly the same. I correctly suspected apostrophes among other characters were being mutated by my code editor. E.g. Two versions of "I'm excited" where one had a straight apostrophe and the second a curly apostrophe.